Temporal difference learning
Introduction
Temporal-difference (TD) learning is a combination of Monte Carlo ideas and dynamic programming (DP) ideas. Like Monte Carlo methods, TD learns from experience without needing the model of the environment’s dynamics. Like DP methods, TD learn estimates from other estimates (bootstrapping) without waiting for final outcome.
TD(0)
\(\begin{aligned} &V(S)\leftarrow V(S)+\alpha(R+\gamma V(S')-V(S))\\ &where \ S:State, V(S): value\ of\ state, R: observed\ reward\ for\ taking\ action,\\ &S':next\ state, \alpha: step\ size\ parameter ,\gamma: discount\ rate\\ \end{aligned}\)
To gain an intuition about the above equation, consider the following.
i.e. if the value of the next state S’ is better than the current state, increase the value of current state as this path leads to a next state of a higher value.
i.e. if current breadcrumb path leads to higher reward, increase value of current state V(S) as it leads to a higher reward path.
Example: Random walk
All episodes start in the center state, C, and proceed either left or right by one state on each step, with 0.5 probability. The episode terminates when either T1 or T2 is reached. A reward of +1 occurs when T2 is reached, all other rewards are 0.
Code
Results
# Generates gif animation
td0_random_walk(0.05, true);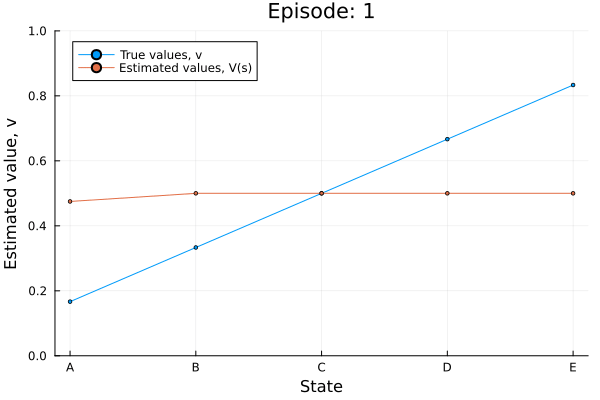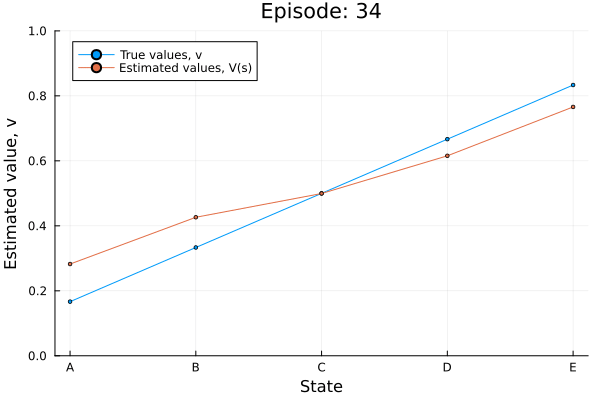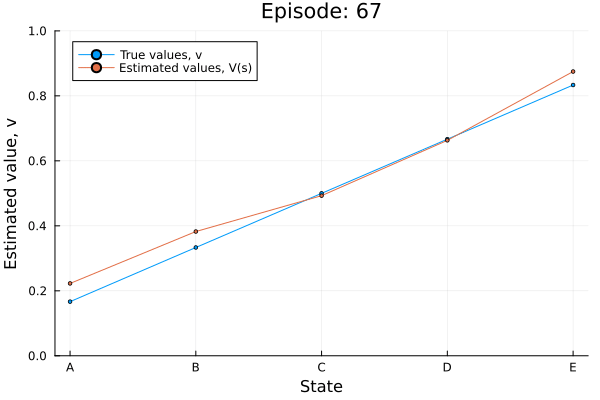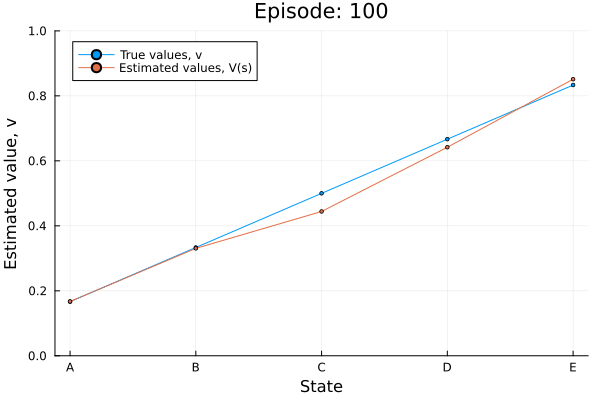
err0 = td0_random_walk(0.05);
err1 = td0_random_walk(0.1);
err2 = td0_random_walk(0.15);
plot([err0 err1 err2], title = "RMS error vs episodes", label=["\\alpha=0.05" "\\alpha=0.1" "\\alpha=0.15"], xlabel = "Episodes", ylabel = "RMS error")
SARSA: On policy TD Control
SARSA learns the action-value function rather than the state-value function. This ‘on-policy’ learns $q_\pi(s,a)$ for a given policy $\pi$ for all states $s$ and action $a$.
SARSA algorithm
Example: Windy grid world
In windy grid world, we have a start position S and goal position G. There is a crosswind upward through the middle of the grid. The actions are the standard four moves: up, down, left, right but in the middle region the resultant next states are shifted upward by a “wind,” the strength denoted by the numbers at the bottom of the grid. Assume that moves at the edges of the grid world are not valid states.
Code
Results
println("Min steps found: ", minimum(step_data))
display(plot(step_data, xlabel = "Episode", ylabel = "No. of steps"))
display(plot(step_data2, xlabel = "Episode", ylabel = "Cumulative Time steps"))Output:
Min steps found: 17

travelled_path = [start]
# Initialise state s, reward
s = start
steps = 0
# Choose action for state with policy π
a = epsilon_greedy(s, sa, Q, 0) # set epsilon to 0 (greedy action)!!
while true
# take action a, observe reward r, next state s'
s_next = (max(1, a[1] - wind[a[2]]), a[2] ) # max op covers hitting north wall case, wind bias added
# choose a' from s' with policy π
a_next = epsilon_greedy(s_next, sa, Q, 0) # set epsilon to 0 (greedy action)!!
# update action and state
s = s_next
a = a_next
push!(travelled_path, s)
steps += 1
if s == goal
println(steps)
break
end
end
gridplot_anim = zeros(max_row, max_col)
windy_anim = @animate for path in travelled_path
gridplot_anim[path...] = 1
(heatmap(gridplot_anim, yflip=true, color=:blues))
end
gif(windy_anim, "windy_gridworld.gif", fps = 5) 
Q-learning: Off-policy TD Control
In Q-learning, the learned action-value function, Q, directly approximates $q_∗$ the optimal action-value function, independent of the policy being followed. The policy still has an effect in determining which state-action pairs are visited and updated. As long as all pairs are updated, convergence is achieved.
Q-learning algorithm
In the algorithm, we are $\boldsymbol{NOT}$ updating action A. Unlike SARSA, the action (e.g. action with max Q) is not followed in the next step - e.g. we are still running $\epsilon$-greedy for the next action. i.e. It does not account for action selection.
Example: Cliff walking (Q-learning version)
Again denote start point S and goal G. Movements are up, down, left, right. Rewards are 0 for the goal, -100 for the cliff areas and -1 elsewhere. Any travesal through the cliff areas sends the agent back to the start point S.
Code
Results
max_reward = maximum(av_reward)
println("Min steps found: ", minimum(step_data))
display(plot(step_data, xlabel = "Episode", ylabel = "No. of steps"))
display(plot(av_reward, xlabel = "Episode", ylabel = "Reward", label = "\$max\\: reward=$max_reward\$"))Output:
Min steps found: 13

travelled_path = [start]
# Initialise state s, reward
s = start
steps = 0
while true
# Choose action for state with policy π
a = epsilon_greedy(s, sa, Q, 0) # set epsilon to 0 (greedy action)!!
# take action a, observe reward r, next state s'
s_next = a
# choose a' from s' which returns max Q value
a_next = epsilon_greedy(s_next, sa, Q, 0) # set epsilon to 0 (greedy action)!!
# update action and state
s = s_next
push!(travelled_path, s)
steps += 1
if s == goal
println(steps)
break
end
end
gridplot_anim = zeros(max_row, max_col)
cliff_qlearning_anim = @animate for path in travelled_path
gridplot_anim[path...] = 1
(heatmap(gridplot_anim, yflip=true, color=:blues, aspect_ratio=:equal, ylimits=(0.5,4.5)))
end
gif(cliff_qlearning_anim, "cliff_q_learning.gif", fps = 5) 
We see that Q-learning learns to travel along the cliff (‘risky area’) to get to goal.
Example: Cliff walking (SARSA version)
Code
Results
max_reward = maximum(av_reward)
println("Min steps found: ", minimum(step_data))
display(plot(step_data, xlabel = "Episode", ylabel = "No. of steps"))
display(plot(av_reward, xlabel = "Episode", ylabel = "Reward", label = "\$max\\: reward=$max_reward\$"))Output:
Min steps found: 17

travelled_path = [start]
# Initialise state s, reward
s = start
steps = 0
# Choose action for state with policy π
a = epsilon_greedy(s, sa, Q, 0) # set epsilon to 0 (greedy action)!!
while true
# take action a, observe reward r, next state s'
s_next = a
# choose a' from s' with policy π
a_next = epsilon_greedy(s_next, sa, Q, 0) # set epsilon to 0 (greedy action)!!
# update action and state
s = s_next
a = a_next
push!(travelled_path, s)
steps += 1
if s == goal
println(steps)
break
end
end
gridplot_anim = zeros(max_row, max_col)
cliff_sarsa_anim = @animate for path in travelled_path
gridplot_anim[path...] = 1
(heatmap(gridplot_anim, yflip=true, color=:blues, aspect_ratio=:equal, ylimits=(0.5,4.5)))
end
gif(cliff_sarsa_anim, "cliff_sarsa.gif", fps = 5) 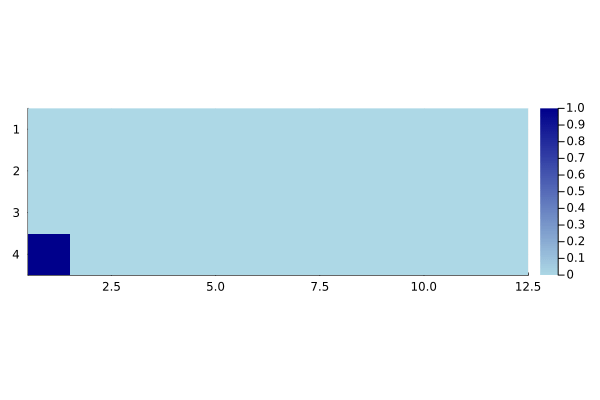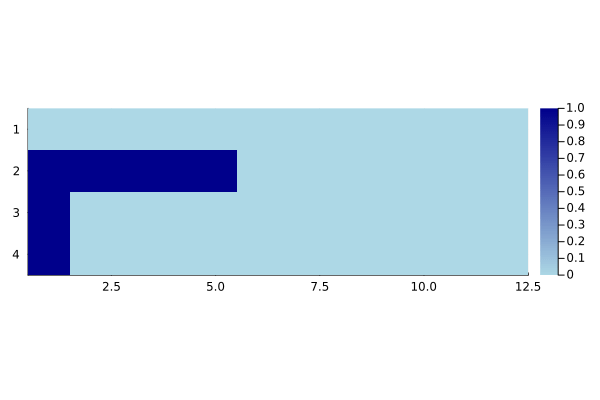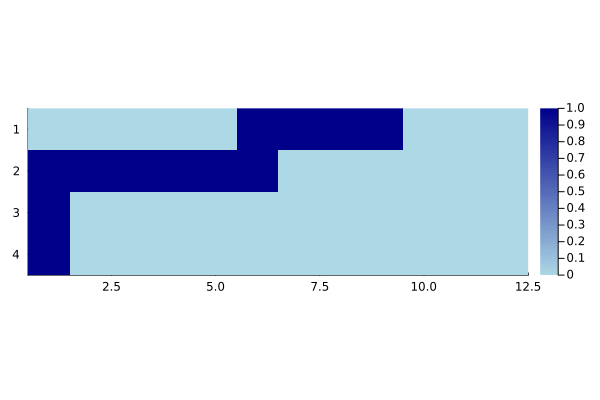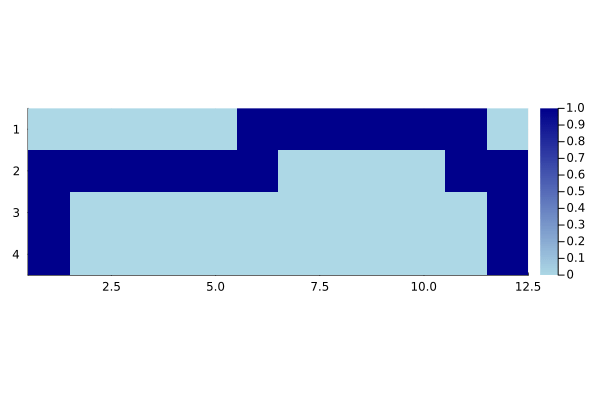
In contrast, SARSA learns to travel a longer but safer route away from the cliff to get to goal as it accounts for the action selection.
References
- Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction